Exposer et rechercher des données bibliographiques avec Zotero, Python et Whoosh
La gestion de métadonnées bibliographiques est un domaine vaste, d’une complexité qui peut être étonnante aux yeux du non-initié. Plusieurs normes et standards s’intéressent à ces métadonnées — particulièrement pour en favoriser l’interopérabilité — qu’on retrouve notamment au coeur des catalogues de bibliothèques informatisés (OPAC). Les notices bibliographiques sont caractérisées par des champs nombreux (dont la liste dépend du type d’ouvrage décrit), généralement optionnels, à longueurs variables et à valeurs multiples. De plus, les valeurs de certains champs sont souvent assujetties à des référentiels terminologiques ou à des listes contrôlées.
C’est dans un petit coin de cet univers que s’est inscrit l’un de nos derniers projets, dont le principal objectif était la création d’une interface de recherche à la fois évoluée et conviviale pour fouiller une riche bibliographie portant sur l’histoire de Montréal, un projet du Laboratoire d’histoire et de patrimoine de Montréal et de Montréal, plaque tournante des échanges, un partenariat de recherche financé par le Conseil de recherche en sciences humaines du Canada (CRSH).
Même s’il s’agissait d’un mandat assez court, cette réalisation est un bel exemple du plaisir que nous avons, chez Whisky Echo Bravo, à cerner au mieux les besoins d’un client, à concevoir une solution sur mesure, adaptée à la fois aux besoins et aux contraintes du projet, autant sur le plan du concept que dans les choix technologiques. L’approche par prototypage nous a permis d’affiner le produit de manière itérative avec le client, sur la base de son utilisation réelle.
L’analyse : évacuer les idées préconçues
Le client était déjà très familier avec Drupal et connaissait notre expérience avec ce système de gestion de contenu (CMS). C’est donc en avançant l’hypothèse d’une plateforme Drupal qu’il nous a abordé pour discuter du projet. En effet, l’écosystème Drupal est riche de plusieurs modules qui, au premier abord, paraissaient fort à propos, particulièrement Biblio, Search API, Facet API. Nous connaissons d’ailleurs très bien chacun de ces modules, pour les avoir utilisés dans nombre de projets et même pour y avoir contribué des améliorations.
Lors des premiers entretiens, nous avons appris que le client apprécierait pouvoir gérer la bibliographie dans Zotero, un outil populaire dans le milieu de la recherche pour gérer les notices bibliographiques de manière collaborative. Nous avons donc avancé l’hypothèse d’une intégration transparente avec Zotero, où les données de Zotero seraient synchronisées automatiquement avec l’index de recherche. Le module Drupal Biblio Zotero paraissait susceptible de jouer ce rôle. Cependant, nous appréhendions les correspondances imparfaites entre les champs de Zotero et ceux de Biblio. De manière générale, il nous semblait excessif d’incorporer au système tout le bagage de Biblio, alors que son rôle, en fin de compte, devait se borner à retransmettre les données à un index de recherche.
Zotero disposant d’une interface de programmation (API), il nous est aussi apparu qu’il n’était peut-être pas nécessaire d’avoir une couche intermédiaire entre Zotero et l’index de recherche; Zotero faisant office de base de données, nous n’avions pas besoin d’un CMS pour gérer ces données en parallèle. Après avoir vérifié que l’intégralité des informations, notamment l’importante classification des notices bibliographiques, pouvaient bel et bien être gérées directement dans Zotero, nous avons dressé une brève liste de conditions devant guider l’architecture du système :
- Toutes les informations sont représentables dans Zotero.
- Toutes les données seront gérées dans Zotero, qui fera office de base de données.
- Le site web n’aura qu’une poignée de pages « statiques » d’information, tout au plus, et ces pages seront rarement modifiées.
- Le système n’a pas besoin de mécanismes de permissions complexes.
- Le système n’a ni besoin de fournir des fonctions collaboratives ou sociales, ni besoin de fournir des interfaces administratives particulières.
- La solution doit être durable, minimiser le coût de maintenance et, outre Zotero, minimiser les dépendances envers des logiciels ou systèmes externes.
- Le nombre de notices bibliographiques n’est pas astronomique (à moyen terme, environ 10 000 entrées).
Ces conditions validées par le client, nous avons pu envisager une architecture simplifiée, constituée des composantes suivantes :
- Un site web offant l’interface de recherche et quelques pages d’information.
- Un système d’indexation des données de Zotero.
- Un script pour la migration initiale d’une partie des données vers Zotero (l’autre partie étant déjà dans un format importable par Zotero).
Ainsi, nous avons retranché Drupal de l’ensemble logiciel. Ceci signifiait non seulement le retrait d’un assemblage relativement complexe de modules PHP, mais aussi l’élimination pure et simple du besoin pour une base de données relationnelle, autant d’éléments qui, eussent-ils été incorporés au projet, auraient inévitablement généré des efforts de maintenance supplémentaires.
Aucun logiciel n’est exempt d’efforts de maintenance, mais l’assemblage proposé sera beaucoup plus frugal à cet égard que ne l’aurait été la solution basée sur Drupal, en plus d’être moins sujet à des risques d’incompatibilité lors des mises à jour.
L’ensemble logiciel
Drupal n’étant plus requis, c’est vers le langage Python que nous nous sommes tournés. L’écosystème Python, riche en outils pour tout ce qui a trait à la manipulation de données, offrait des solutions simples et performantes pour chacune des composantes du projet. C’est donc sur les éléments suivants que nous avons finalement développé nos trois composantes d’interface Web, d’indexation et d’importation de données :
- PyZotero pour communiquer avec l’API de Zotero.
- Whoosh pour moteur de recherche à facettes. La recherche à facettes était une exigence clé du projet et Whoosh a été un élément important nous faisant opter pour une solution en Python. Notre moteur de recherche préféré, Solr, aurait exigé la maintenance d’un second ensemble logiciel ou son externalisation, puisque Solr est basé sur Java. Whoosh est suffisamment riche en fonctionnalité — bien amplement pour les besoins du projet — tandis que la capacité de Solr à monter en charge n’était pas utile au projet. L’interface de programmation de Whoosh est par ailleurs exemplaire. L’attention apportée à la simplification de paramètres souvent compliqués dans d’autres moteurs de recherche y est manifeste et un beau jeu d’extensions pré-réglées facilite le prototypage rapide (après un après-midi de première exploration de Whoosh, nous avions déjà des résultats fantastiques).
- Flask et Bootstrap comme fondations pour l’application Web. Flask et son écosystème de bibliothèques bien ciblées permettent de construire une solution vraiment sur mesure, sans plus ni moins que ce qui est utile au projet.
- citeproc-py pour la mise en forme des notices bibliographiques. La bibliothèque JavaScript citeproc-js, qui est employée par l’équipe de Zotero, est légèrement plus riche en fonctionnalités, mais citeproc-py couvrait tout de même amplement les besoins du format Citation Style Language (CSL) que nous devions créer pour le projet et avait l’avantage d’être native à Python, donc parfaitement harmonisée au reste du système et minimisant l’impact sur la maintenance.
- Markdown pour les contenus statiques, facile à modifier par le client tout en éliminant le risque d’erreurs dans la sortie HTML.
- Gunicorn comme serveur HTTP, avec nginx en proxy. Nous apprécions beaucoup nginx, éprouvé, performant et élégant par sa simplicité.
La recherche et la navigation dans la bibliographie ne font aucun appel à l’API de Zotero. Toutes les données utiles sont stockées dans la base de données de Whoosh. Cette caractéristique est essentielle, d’une part parce que l’API de Zotero impose (comme il se doit) des limites sur le débit des requêtes et, d’autre part, parce qu’autrement la fiabilité de notre système serait à la merci de la disponibilité et du temps réponse du service de Zotero. Par conséquent, seul le système d’indexation communique avec Zotero, ce qu’il fait régulièrement pour mettre à jour l’index de recherche. Advenant une panne de Zotero, il ne fait que rater une opportunité de synchronisation et, pendant ce temps, l’outil de recherche continue à fonctionner normalement.
De même, les notices bibliographiques sont mises en forme à l’avance et stockées dans la base de données de Whoosh au moment de l’indexation, évitant ainsi la répétition des traitements par citeproc-py.
En ce qui a trait à la migration dans Zotero des données sources, comme à chaque fois dans ce genre de travail, l’opération a permis de déceler des erreurs et des incohérence dans les données sources, un ensemble de près de 4000 notices bibliographiques. Les expressions régulières furent utilisées à profusion pour extraire les données, les valider et les transformer en fonction des formats attendus pour chaque champ. Certaines corrections ont dû être faites manuellement, alors que d’autres furent automatisées. Le catalogage des notices bibliographiques dans la classification hiérarchique nous a posé un problème particulier : en effet, dans les données sources, les libellés des termes ne correspondaient pas toujours à ceux des termes de référence. Puisqu’il n’était pas envisageable de corriger manuellement un tel volume de données, nous avons utilisé la distance de Levenshtein (qui mesure la similarité entre deux chaînes de caractères) pour trouver les meilleures correspondances. Grâce à la richesse de la bibliothèque Python, nous n’avons pas eu à coder l’algorithme de mesure, concentrant nos efforts à l’optimisation de la distance maximale pour l’acceptation d’un terme candidat. Cette technique nous a permis de classer correctement toutes les entrées, à l’exception d’une seule, qui a dû être traitée manuellement.
Le résultat
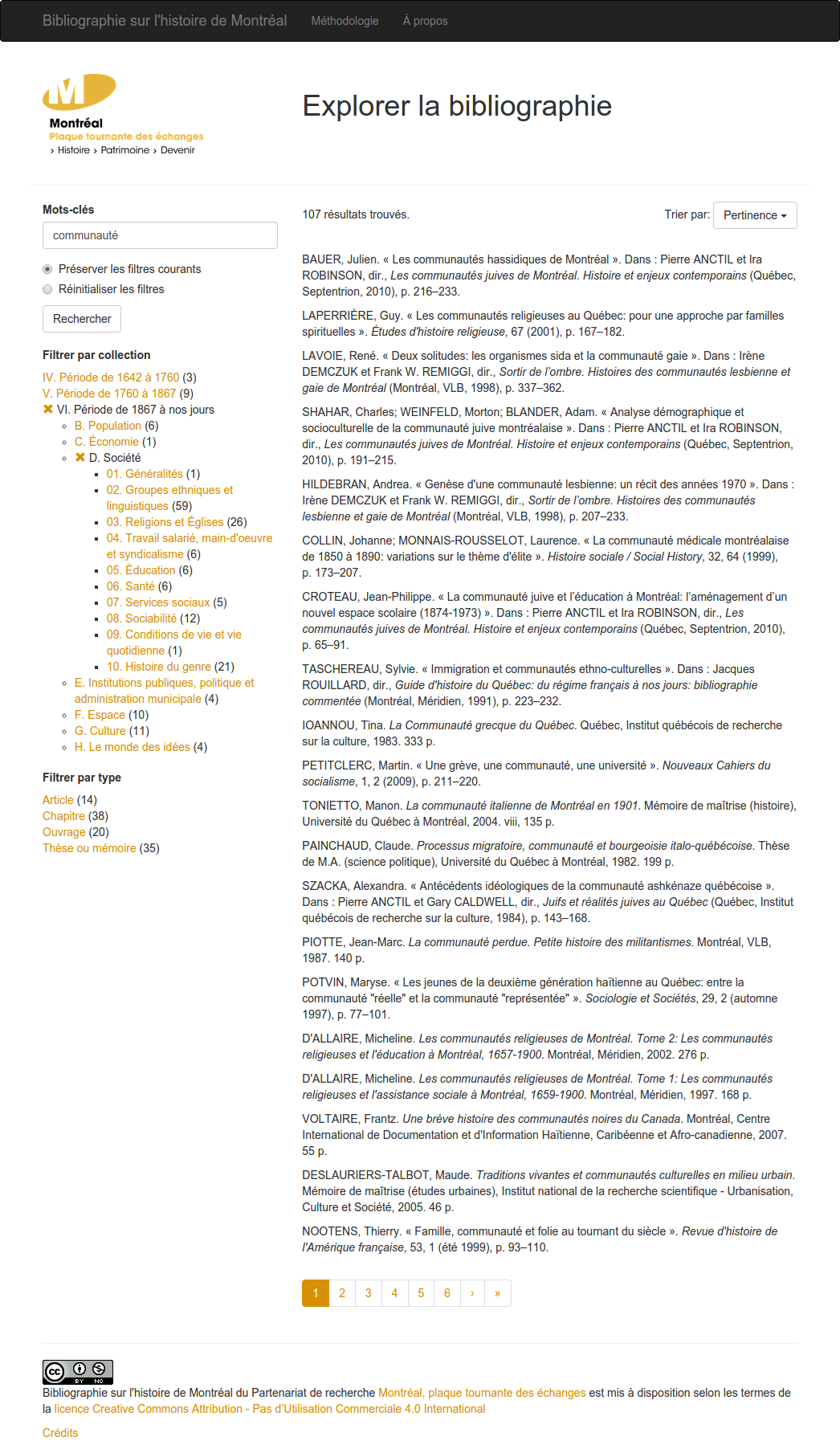
Un aperçu du prototype d’interface de recherche à facettes pour la Bibliographie sur l’histoire de Montréal.
Le résultat du projet est un site certes minimaliste, mais fiable, bien adapté aux besoins des chercheurs qui dépendent de cet outil et livré dans les délais prévus. La performance offerte par Whoosh s’avère parfaitement satisfaisante, tel que constaté lors des premiers prototypes. Nous n’irions sans doute pas jusqu’à le recommander pour une collection comptant plusieurs centaines de milliers de documents sur un site à fort achalandage, mais nous n’hésiterons pas à l’utiliser comme alternative à Solr dans d’autres projets plus modestes.
Chacun a joué son rôle de manière exemplaire, d’abord le client en nous accordant toute sa confiance et en gardant l’esprit ouvert à des solutions fort différentes des hypothèses initiales, puis nous, en faisant comme d’habitude. :-)
Malheureusement nous ne pouvons pas encore vous inviter à essayer cet outil, qui n’est encore offert qu’à un groupe restreint de chercheurs. Cependant notre client a bien l’intention de l’ouvrir plus tard au grand public; nous nous ferons un plaisir de retransmettre l’information au moment opportun. En attendant, plusieurs évolutions sont envisagées. Les échanges d’idées entre nous et le client laissent entrevoir plusieurs possibilités, par exemple :
- L’éclatement de la classification des notices bibliographiques (qui s’inspire de la classification proposée dans un ouvrage phare de la discipline) en plusieurs facettes complémentaires (décloisonnant les éléments et multipliant les scénarios de recherche possibles).
- La possibilité d’effectuer des recherches textuelles par champs pour augmenter la précision des résultats.
- La génération de balises OpenURL COinS dans la sortie HTML, permettant à un utilisateur d’incorporer, en un clic, n’importe quelle notice bibliographique dans sa propre bibliographie (avec Zotero, Mendeley, ou tout autre logiciel reconnaissant ce standard).
Qui sait, nous aurons peut-être encore beaucoup à dire sur ce projet.
Mise à jour, 9 mai 2015 : la Bibliographie sur l’histoire de Montréal est désormais en ligne et accessible au grand public!
Commentaires